Approach
Motivation
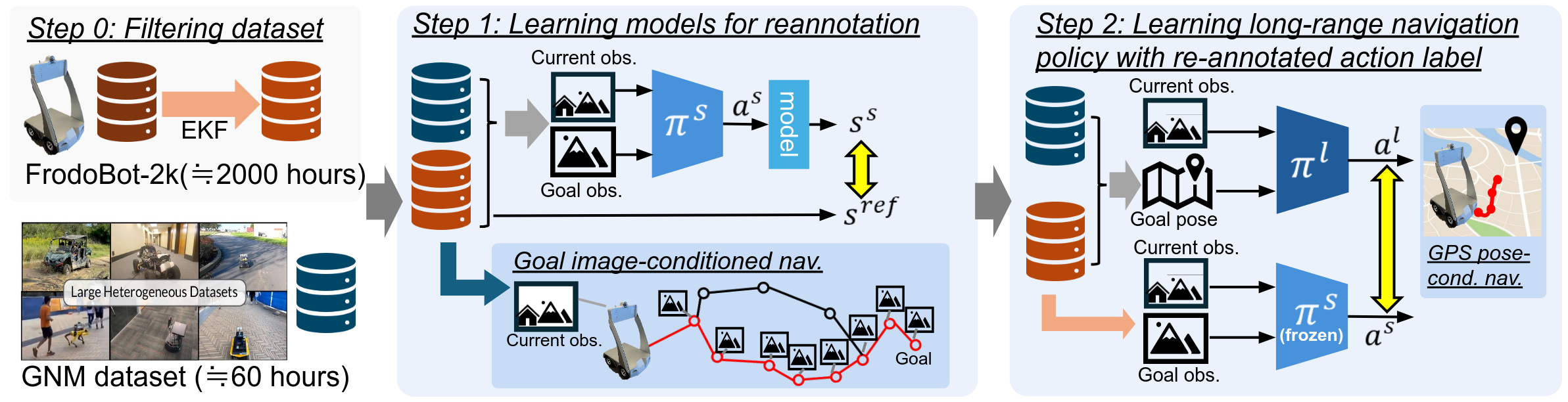
Our goal in this work is to enable end-to-end training of navigation policies for ground robots that can generalize broadly to a wide range of environments and follow reasonable conventions such as staying on paths and avoiding collisions. This requires large amounts of training data, which we can obtain from low-cost robotic platforms and crowd-sourced data collection. While these sources can provide large amounts of data, this data is of low quality: the actions might not be consistently good, and even when they are, the sensors and state estimators on the robot might not allow for accurately estimating the next waypoint that corresponds to the human driver's intent. To address this, we propose Model-Based ReAnnotation (MBRA) to relabel data. We train the Long-range Goal pose-conditioned Navigation policy (LoGoNav) with its relabeled actions.
Model-based Re-Annotation (MBRA)
In MBRA, we first apply an extended Kalman filter to denoise the action commands in the noisy dataset and prepare a set of small publicly available navigation datasets with accurate action labels. Filtering the dataset is not enough to mitigate noise, so we train a re-annotation model with model-based learning. Since model-based learning is robust for noisy data, we can incorporate both the accurate GNM dataset and the large but noisy FrodoBot 2k dataset to train the re-annotation model. This model learns to predict actions between temporally close image frames and therefore we can directly use this model as a short-horizon goal-image conditioned navigation policy. We use the re-annotation policy to create more useful action labels for trajectories in the large dataset and then train the long-horizon navigation policy on this re-annotated dataset, which can robustly navigate the robot toward goal poses about 50 meter away.
Dataset
We use a FrodoBots-2k dataset, which was collected in more than 10 cities around the world with remote teleoperation. The FrodoBots-2k dataset includes 2000 hours of gameplay and was collected as part of FrodoBots AI, where users explore locations worldwide by teleoperating robots to reach target positions. The FrodoBots-2k dataset is significantly larger than other publicly available datasets for vision-based navigation tasks. As shown in our paper, the full version of the FrodoBots-2k dataset is more than 25 times larger than other datasets and includes a diverse set of real robot trajectories teleoperated by humans. The FrodoBots-2k dataset includes the sequence of the front- and back-side camera image, GPS position, IMU sensor and wheel odometery for about 2000 hours.
We also evaluate the ability of MBRA to enable the use of non-robot data. We reannotate 100 hours of action-free in-the-wild YouTube videos, listed in LeLaN project, and train a policy with the generated actions. These videos include inside and outside walking tours from 32 different countries across varying weather conditions, time of day, and environment types (urban, rural, etc.).
In addition, we use the GNM mixture containing multiple dataset with different robotic platforms such as GO Stanford2, GO Stanford4, HuRoN(SACSoN), RECON, SCAND, CoryHall, TartanDrive and Seattle. Since all these dataset are collected with the robots with rich sensor system and teleoperated by experts, action labels are more accurate.
Evaluation around the world
To assess generalization capabilities, we deploy our navigation policies on robots in diverse environments across 6 countries: USA, Mexico, China, Mauritius, Costa Rica, and Brazil. In total, we collect 24 topological graphs and evaluate each goal trajectory. To the best of our knowledge, we are the first to conduct a global evaluation for visual navigation.
Experiments
Long-distance Navigation (LogoNav)
We evaluate our trained policy on long-distance navigation, where the policy must reach a target position several hundreds of meters away from the start point without collision or getting stuck.
Public park : 330 meters
University campus (human-occupied space) : 280 meters
Cross Embodiment Navigation
We deploy the long-range goal pose-conditioned navigation policy on other robot embodiments, including a Unitree GO1 quadruped robot, and Vizbot, a Roomba-based prototype mobile robot in indoor and outdoor settings. With the GO1 and Vizbot, we mount different cameras to investigate the cross-embodiment performance of our policy. We achieve good goal-reaching behavior in long navigation about 100 meters, highlighting the policy's ability to generalize.
Goal image-conditioned navigation (MBRA)
In addition to LoGoNav, we evaluate the goal image-conditioned navigation policy, which results from our MBRA method. The policy resulting from MBRA can navigate the robot towards a goal up to 3 meters away, so we can use a topological memory to move to a goal position further away, similar to other vision-based navigation approaches. To collect this goal loop, we teleoperate the robot and record image observations at a fixed frame rate of 1 Hz. To deploy the policy, we start from the initial observation and continuously estimate the closest node from the topological memory. At each time step, we feed the image from the next node as the goal image to our policy to compute the next action. Our MBRA enables us to navigate the robot toward goal poses far away with visual imformation only.
BibTeX
@misc{hirose2025mbra,
title={Learning to Drive Anywhere with Model-Based Reannotation},
author={Noriaki Hirose and Lydia Ignatova and Kyle Stachowicz and Catherine Glossop and Sergey Levine and Dhruv Shah},
year={2025},
eprint={2505.05592},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2505.05592},
}